Lab 6. The Three-Dimensional Viewing Pipeline
M. Stone and A. Pshenichkin. 11.21.04.
Cleaning Up the Debugging Process
Prolonged use of our LogManager revealed some major issues. Most notably, it became clear that we needed channels, not levels: we found ourselves repeatedly inserting and deleting lines, making the LogManager little better than a bunch of print statements in certain situations. Instead of changing how verbose the logging output was, we needed the ability to filter log messages by type, allowing us to focus our attention on one or two types of actions, such as memory allocation or the contents of matrices as they go through the pipeline. This led us to switch to libcwd, the C++ Debugging Support Library, which has a variety of very useful features, especially with regard to memory management. This tool has, ultimately, greatly enhanced our ability to debug our code.
3-D Matrix Transformations
Going to three dimensions requires being able to manipulate 4x4 matrices. This functionality was already there, mostly, having been added in previous labs, including, of course, truly arbitrary rotation using quaternions. Unfortunately, while we had been careful, in those labs, to use 4x4 matrices to represent our transformations, we had been lax about representing our Primitives with 4-vectors. This meant that it was necessary to refactor almost all of our existing code to make it fully three-dimensional.
3-D Perspective Viewing Pipeline
This lab deals with means for representing three-dimensional objects in two-dimensional views. The simplest of these, orthographic projections, just throw away the z coordinate of the primitives being drawn. This is a an affine, or parallel, projection. Affine projections preserve parallelism in images. Perspective projections, in contrast, do not. Instead, parallel lines converge as they go off into the distance. While parallel projection has many uses, for example in CAD programs, perspective projection is far better suited for emulating the world as we see it.
We can imagine a perspective view transformation as looking through a window into a big box containing our objects. That window is the screen, and its coordinates are expressed in terms of u and v. The View Plane Normal vector defines the facing of our screen surface. Given a VPN and a VUP, we can assume that the u axis is VUP x VPN, and then calculate a new VUP as VPN x u, giving us an orthonormal basis. Thus, altering the direction of VUP essentially rotates our entire scene.
A point and a vector in three-space define a plane. Thus, we need a View Reference Point, which defines the position of the projection area. The VRP and VPN define the position viewplane, and VUP gives us an orientation. We must also assign a Center of Projection. In quasi-real terms, the COP is where the camera lens is. We see things as they appear when they are projected onto the viewplane, which lies between the COP and the scene. Thus, if we project rays out from the COP to the corners of the viewplane and then extend them past, we get a rectangular pyramid.
Now we define F and B, the front and back distances measured from our VRP along the VPN, as the near and far bounds of our view volume. Cutting the pyramid created above to only include the region between F and B along the z axis (we do this step after aligning the z axis to the VPN), we create the view frustrum.
Thus, if we move our COP further from the VRP, we reduce the foreshortening factor of the image, while making lines perpendicular to the viewplane less visible. Assuming the cube is behind the viewplane and not touching it, the cube also seems to get bigger as we enlarge the distance: this is because the viewing frustrum has steeper sides, reducing the total volume that it encloses. If we modify the size of the view window, in contrast, we are altering the size of the base and top of the frustrum rather than the inclination of its sides. This does, of course, have the effect of making our object seem bigger because we are focusing more on it. Reducing the window size also has the same effect on foreshortening as moving the COP further away, since the viewing frustrum also gets steeper. Truly zooming in or out on something would require altering both the COP distance and the viewing area size simultaneously, so that the viewing frustrum grows and contracts without changing its slope. Note that this is much easier to accomplish by just shifting the VRP.
The first major stage of our viewing pipeline is a transformation to the Canonical View Volume (CVV). We begin by orthonormalizing u, VUP, and VPN, as described above. Then we apply a translation to move VRP to the origin, and a rotation to align our u/VUP/VPN coordinate system with the x, y, and z axes. We then translate the Center of Projection to the origin, shear in z to align the pyramid, and, finally, scale to the Canonical View Volume.
Accomplishing the latter is a rather involved process. Given our transformed VRP, which we shall call VRP', we find a B' by adding the z coordinate of VRP' to B. We can then scale by [ (2 * VRP') / (du * B') , (2 * VRP') / (dv * B') , 1 / B' ], where du and dv are our u and v dimensions.
This puts us into CVV coordinates. (It is now possible to clip lines to the view volume at this stage, before data is lost in projection.)
Having transformed ourselves into CVV coordinates, we now project. To do so we add the matrix
[ 1 0 0 0 ] [ 0 1 0 0 ] [ 0 0 1 0 ] [ 0 0 1/d 0 ]
where d is VRP'z / B'. This takes [ x , y , z , 1 ] to [ x , y , z , z/d ], which is the same as [ xd/z , yd/z , d , 1 ].
Finally, having flattened the image, we scale it to the screen, converting our 4-vectors to [ xd/z , yd/z , z , 1 ]. The first two values give us our screen coordinates one we translate by ( x/2 , y/2 ) to compensate for the fact that our screen coordinates start from a corner and not the center. We can then use the z value to figure out the order of objects in a z buffer algorithm.
For example, transforming a cube oriented to be parallel to the x, y, and z planes with opposing corners at ( 0 , 0 , 0 ), ( 1 , 1 , 1 ) with the COP at ( 0.5 , 0.5 , -4 ) and the VRP at ( 0.5 , 0.5 , -2 ) and a window size of ( 1 , 1 ) results in the following x, y coordinates for its points:
| Original point | Transformed point |
| ( 0 , 0 , 0 ) | ( 150 , 150 ) |
| ( 1 , 0 , 0 ) | ( 50 , 150 ) |
| ( 0 , 1 , 0 ) | ( 150 , 50 ) |
| ( 0 , 0 , 1 ) | ( 175 , 175 ) |
| ( 1 , 1 , 0 ) | ( 50 , 50 ) |
| ( 1 , 0 , 1 ) | ( 75 , 175 ) |
| ( 0 , 1 , 1 ) | ( 175 , 75 ) |
| ( 1 , 1 , 1 ) | ( 75 , 75 ) |
Fun with Cubes
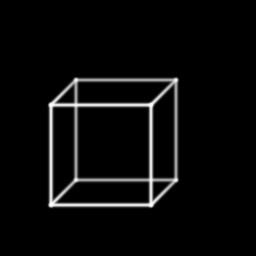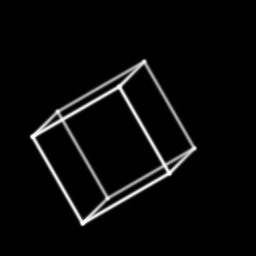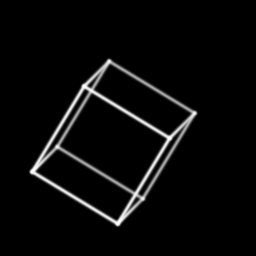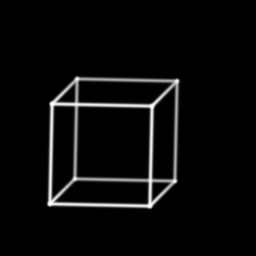
- A Cube in Three Dimensions: This is a simple required image.
- A Cube in 3-Point Perspective: A cube in three-point perspective.
- Cube Rotating around View Plane Normal (VPN): This image presents a cube rotating in the viewing window. The rotation was accomplished by rotating the View Up Vector (VUP) around the View Plane Normal, the +z axis ([0 0 1 0]).
- Rotating Cube, Without Perspective Correction: By discarding the perspective component of the transformation, we can see the cube rotating around the same axis but with parallel lines remaining parallel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
M. Stone and A. Pshenichkin.