
blackDisk

redDisk

clip

cone

diskCase

pen

pliers

stopsign
jumpingToy

ethernetCase

bottleCap

cat

sunglasses

tapeDispenser

wireCutters
blackDisk |
redDisk |
clip |
cone |
diskCase |
pen |
pliers |
stopsign |
jumpingToy |
ethernetCase |
bottleCap |
cat |
sunglasses |
tapeDispenser |
wireCutters |
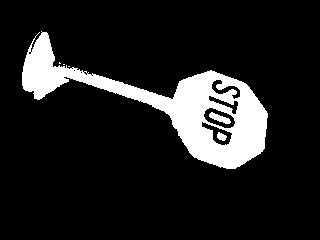 before grassfire transform |
 after grassfire grow |
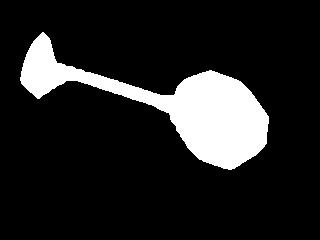 after grassfire shrink |
 major axis and perimeter |
 radial projection lines radial projection lines |
| obj in \ result | black disk | red disk | clip | cone | disk case | pen | pliers | stop sign | jumping toy | ethernet case | sunglasses | wire cutters | bottle cap | tape dispenser | cat | reject |
| black disk | 2 | 2 | 1 | 5 | ||||||||||||
| red disk | 5 | 3 | 1 | 1 | ||||||||||||
| clip | ||||||||||||||||
| cone | 10 | |||||||||||||||
| disk case | 2 | 3 | 5 | |||||||||||||
| pen | 7 | 1 | 2 | |||||||||||||
| pliers | 10 | |||||||||||||||
| stop sign | 9 | 1 | ||||||||||||||
| jumping toy | 10 | |||||||||||||||
| ethernet case | 10 | |||||||||||||||
| sunglasses | 10 | |||||||||||||||
| wire cutters | 10 | |||||||||||||||
| bottle cap | 10 | |||||||||||||||
| tape dispenser | 10 | |||||||||||||||
| cat | 10 | |||||||||||||||
| reject | 1 | 1 | 1 | 3 | 4 | |||||||||||