For this lab Sven and I decided to join forces in
creating a Konane agent. We talked for a while about how to abstractly
measure the quality of a board without expanding it. After much
discussion and hemming and hawing, we decided that it would be easier
to make the computer think for us. To these ends we created a
classification system for each piece on the board. We thought that
classifying each piece up to rotational symmetry without respect to
board position would provide expressive enough variability. More
explicitly, we chose to classify whether or not a piece was vulnerable
from a particular direction and whether or not a piece could attack a
particular direction as its pertinent state values.
Representation
This lead to the following classifications of states;
some of the non-obvious systems of vulnerabilities are caused by double
jumps (sometimes from multiple directions):
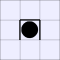
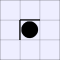
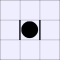
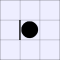
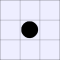
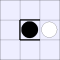
A white piece indicates that black can jump in that direction, while a
thick bar means that black cannot be jumped from that direction.
| Number of vulnerabilities: | |||||||
| 0 | 1 | 2A | 2B | 3 | 4 | ||
| Number of pieces I can take: | 0: | 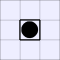 |
 |
 |
 |
 |
 |
| 1: | 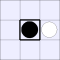 |
 |
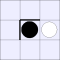 |
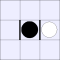 |
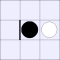 |
 |
|
| 2A: | 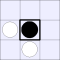 |
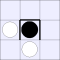 |
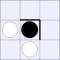 |
|
|||
| 2B: | 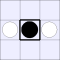 |
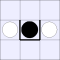 |
|
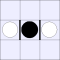 |
|||
| 3: | 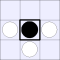 |
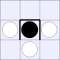 |
|||||
| 4: | 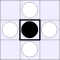 |
||||||
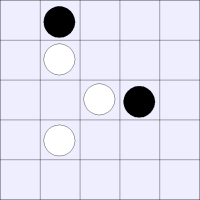
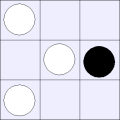
Consider the following board state. Here the center black piece in is in state 1-2B, while the lower right piece is in state 2A-0.
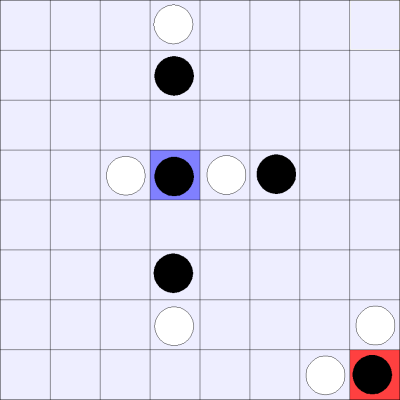
Really, the representation is fairly simple, except for the special case. It is long, but simple. Matt was hoping that this would allow his GAs enough space to come up with interesting answers, while maintaining a basic simplicity.
Since this left us with 21 basis vectors for our space (42 if you want to count our opponent's states separately), we decided to collapse some of our states for tractability. Our simplified state consists of an integer keeping track of the number of possible attacks and a boolean that holds whether or not the piece is vulnerable to attack. This brings the basis down to 9 states (18 if we wish to represent our opponents pieces in the space); we opted to have states for both players' pieces, as we felt that not evaluating an opponent's position separately would be myopic.
Abstract State Space Discussion
An ideal state space, would map precisely onto the set
of possible boards, such that every board representation would have
exactly one set of coefficients in the state space. An ideal state
space, would also be pleasant to search, meaning that it would be
smooth and possess exactly one global maximum and no other local maxima.
A space like this would be difficult to work with,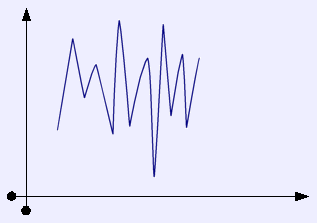 |
while it would be easy to search in this one.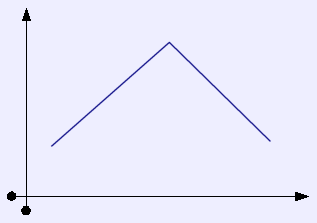 |
Unfortunately, there are ways in which our space is not an ideal space. There exist boards that have meaningfully different strategic values, but whose coefficients for our basis vectors would be identical.
These boards are meaningfully different from each other, but
are represented by identical vectors in our state space: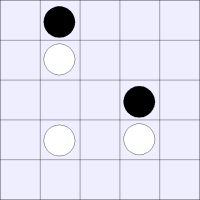
 |
Notice how the same jump (the single jump), will lead to two
states in which different players win.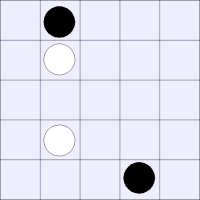
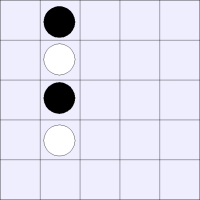 |
An evaluator is said to operate on our state space, when it takes the board that it receives, calculates the vector representing that board in our state space (which is to say analyzes each piece on the board and determines which of the above states it belongs to and increments the appropriate coefficient in the vector), and returns a results based solely upon the generated vector.
Evaluators that operate on our state space cannot differentiate between two states such as the ones above, which do have identical vectors in our space. This is because our space does not take into account relationships between groups.
One could define a state space that took into account possible counters to each attack and vulnerability or even examined 2nd degree, or nth degree, counters. Such spaces would have many times more coefficients then ours does. Sven's intuition is that the benefits of this further subdivision would not be great (except during endgame, when such distinctions could act rather like minimax depth). Which is Matt's argument against such an approach, since it would be expanding the states implicitly via short-circuited logical statements, and thus violating the rules of the tournament.
One could imagine an evaluator that would abide by the rules of the tournament and yet still manage to differentiate between the above states. For example an evaluator could divide the board into sub-sections and evaluate based on the contents of those sections. Some interesting research has already been done in this area; however, it does not seem to apply well to the project of writing an evaluator, but could be useful in fine tuning the search tree. In the above example, a 3x3 sub-board would be sufficient to differentiate between the board states.
Clearly these states have different, if not inherently
obvious, values.
 |
However, brief calculation (2 options per 9 spots, times 2 for whether black or white is in the upper-right) shows that this space has 2^10 basis states. While some could be removed based on rotational symmetry, this still leaves an unwieldy number of states. Thus we feel that such a space would be difficult to search and, to make it tractable, one would have to make too many simplifying assumptions, causing a loss in the expressive power of the basis. Furthermore, to ensure this kind of predictive ability, one would have to consider all possible ways in which a 3x3 board could fit into an 8x8. Thus making any actual attempt to work with this kind of basis, even more unwieldy or necessitate more simplifying assumptions.
What our classification of states has tried to do, is collapse those states which have a small difference between them, while leaving those states that are more orthogonal. In collapsing from the 40 state representation to the 19 state representation, we have assumed a step-like function of badness, in which a transition from one vulnerability to two, is far less significant then transitioning from zero to one.
We imagine that the real badness curve looks like this: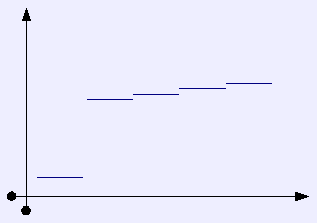 |
-> | While our simplification would have it look like this: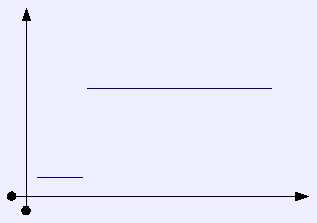 |
Sven feels that our search space is likely to be smooth and have nice symmetries that lend themselves to hill climbing algorithms; whereas, I do not feel confident enough in my intuition to hazard a guess as to the true nature of the search space. In fact, I feel that a hill climbing algorithm based on intuition is likely to find a local, but non-global maximum, since our intuition is probably good, but would surely fail to consider unorthodox things that might be important.
Abstract Evaluator Discussion
Given the preceding definitions of state space and
basis states, we theorized that an evaluator function is simply a
function, that takes the coefficients of our basis states for a given
board configuration and returns a number. Thus we would have to search
for the best 18-variable equation out of the laughably small space of
all possible such functions.
Fortunately, a space of functions can be estimated via a finite degree
Taylor or Fourier Series. Thus, we could restrict our search to the
coefficients on the set of fifth order, 18 dimensional Taylor Series.
Sadly, this leaves us with 18^6 constants to search through. We could
probably restrict this to merely the set of third degree, 18
dimensional Taylor Polynomials without much loss; however, even this is
a little larger than we would like.
We instead, completely without justification, assumed that each basis
state of our space was independent, so that we would only have to
calculate 18 different Taylor Polynomials of third degree. Thus leaving
us with only 54 values to determine. Once again, we felt that some sort
of simplification was in order, so we decided to restrict ourselves to
two different function spaces.
One is the set of functions a*x^b, where a and b
are real numbers and x is the coefficient of a basis state. We hoped
that, by allowing complete variability of the exponent, we would be
searching a comparatively large space with a small number of unknowns.
The other idea we had was to allow each basis state coefficient to be
modified by a function from a small set of representative functions.
Under this formulation each basis state coefficient, x, would undergo a
transformation of the form a*f(b*x), where a and b are real numbers and
f(x) is in an element of the set of functions { x, x^2, 1/x, ln x }.
These functions were chosen, because the each have drastically
different behavior when x is small and when x is large, thus hopefully
providing a full, representation of the space we are trying to
approximate. This also restricts the number of things we have to vary
in our representation to 54, however, only 36 of these variables are
numbers. The other 18 of which are selections of a function from the set we provide.
Thus armed with a representation we may now be able to fight this
beast, by throwing massive amounts of processing power against it.
The Good Fight
Essentially paralleling our feelings about this space,
Sven and Matt attempted to create different approaches to developing an
ideal evaluator.
Armed with his intuition, Sven attacked this problem with a hill
climber and likely initial conditions. Although the hill climber that
he had time to implement before the tournament only generates one
random child and then compares it to the parent. The Grand Plan
involves a slotted hill climber.
This hill climber would start with a relatively large shiver value
would generate all children for a particular parent, and select the
best. After it discovers a maxima for a particular shiver value, it
would reduce the shiver value and repeat the process. This would allow
it to find the general area of a local maxima more quickly, and then
narrow its focus, to find the exact value.
Unfortunately, this space does not have perfectly deterministic
comparisons between children. When to items are compared the "better"
evaluator does not always win (as can be seen in the winning team at
the tournament not having a perfect record). What more realistically
happens is that there is a chance that either team will win and the
chance is biased by the relative skills of the evaluators. Sadly, some
evaluators can prey upon the weaknesses of another evaluator and defeat
it while not being as versatile an opponent as the one that loses.
Matt enters this fight without the armaments of Sven and opted to go
the GA route to a solution instead. Currently his GA randomly
initializes a population, bubble sorts it according to victory, and
then has a probability of mutating each member of the population with
the probability scaling up as it approaches the losing side of the
vector. Due to time constraints both entries in the tournament used
Sven's simple hill climber; however, Matt too has a Grand Plan.
In Matt's ideal GA recombination would also be used to increase
variability in the population.
Recombination would take the form of two separate cross over
probabilities. Each set of weights (the weights on your own and the
weights on your opponent's states) would have a chance to crossover
independently of each other, so that either, both, or neither could
crossover on any particular recombination. Each child would then also
have a chance of mutating. Ideally, the top two or three members of
each generation would be recorded, so that once the entire group had
reached its population limit, they could all be dueled to see if a
possibly superior answer had come and gone.
Sven rightly points out that Matt's method of finding these things is
computationally expensive in the extreme, but Matt does not feel that
Sven's climber will find a global maximum and is more likely to get
stuck at a local one.
Results
We feel that the single most promising result for us
is that the winning team used a weighting on a state space that is a
strict subset of our state space. Thus we feel confident that we could
develop an answer as good as that one given time. We may in fact, over
the next few weeks run our Grand Plans from above, so watch
this space if you wish to know whether those investigations bear fruit.
Statistics
The following statistics were gather from a few sample runs of our agent
|
|
|
--Update (Sven's hill climbing progress)
After the semester ended I spent a bit of time fooling around with my hill climbers. Matt and I thoughtfully kept a copy of all the executables for the other konane AIs entered in the tournament.. Because of that, we can use a Perl script to re-run the original tournament with a new entry and see how we would have done.Thus far the results have been disappointing. The products of my hill climbing rarely beat Lisa's entry, and almost always lose to team 5 (the tournament champions). As we mentioned in the conclusion, Matt and I are of the opinion that we really ought to be able to beat any of the other AIs in the tournament, because we think that team 5 used an evaluator that was found by searching manually searching a subspace of the space that we defined for our search algorithms.
So what is going wrong? In order to cut down on search time, Matt and I have taken all the random elements out of our minimax algorithm. The result has been that evaluators with reasonably similar coefficients almost always tie each other. However, two evaluators that tie against each other may fair very differently when entered in a replay of the tournament.
This suggests some troublesome things about the nature of our search space. In order to be able to effectively search, we would like the evaluators to display something close to an unambiguous ordering. But our current means of comparing evaluators will not easily give us such an ordering.
I can think of two ways of responding to this problem. We could turn off alpha-beta pruning and put back in the random element. Of course, this would greatly increase our search time. And while I do think that introducing the random element will make the comparison function a little better, I don't think that it will be enough to completely solve the ambiguous ordering problem.
My second response feels a bit more promising.
We could rate the outcome of each game between AIs not simply in terms of who won and lost, but by the number of remaining jumps that the winner has when the game finishs. More generally, we could run the search algorithms using a comparison operator defined relative to any “arbiter” evaluator function. The job of the arbiter would be to rate the quality of the winner's final board position.
This approach gives our search algorithms a bit more information to work with, and I think it should go a long way toward improving the quality of my results. Unfortunately, my internet access is currently very limited, so I won't be able to test any of this out until after break.
Last modified 2003-10-07 22:15 EST